
cavendish
edgar
Recently Published

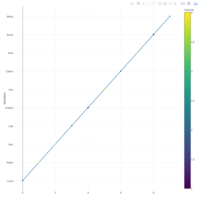
carlo engagement
Cantidad de follower hablando sobre un tema

Ama Engagemet
Es la frecuencia en twittear de los follower del candidato dentro de la red de twitter

Publish Plot
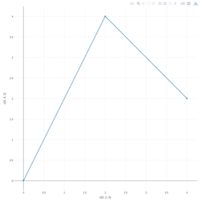
reinaldo frecuencia tweets

Publish Plot
Reinaldo frecuencia twitter



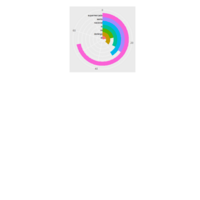
Circular-SuperMercados
Terminos frecuentes asociados a super mercado bravo














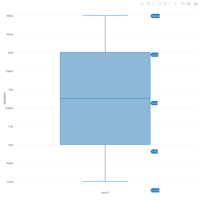
boxplot 4 universidades
apec, intec, ucamm, pucs











BarPlotTricomTresK
claramente vemos los post con mayor y menor exito en este caso
el numero 1 es el peor y el mejor el numero 2, siendo el intermedio el 3

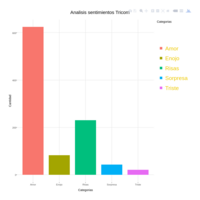
RadarChartTricom
estudio 1 telefonicas

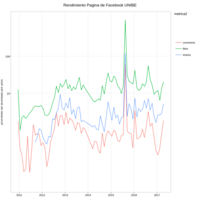
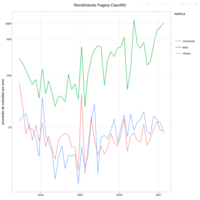
RendimientoPaginaTricom
de 2013 a 2017

grafico 2 tricom
4 usuarios con sus opiniones

Tricom commnality ver graph 1
alternativo al grafico 1

TricomCommonality (graph 1)
palabras que mas se repiten con al menos en este caso 20 veces

RadarChartConLeyenda
#Para hacer la grafico arana
library(fmsb)
radarchart(centros,maxmin = T,axistype = 4,axislabcol="slategray",
centerzero=F,seg=8,cglcol="grey67",
pcol=c("green","blue","red"), col=c("green", "blue","red"))
#hacer la leyenda
leyenda<-legend(1.5,1, legend=c("Cluster 1", "Cluster 2", "Cluster 3"),
seg.len = -1.4,
title = "Clusters",
pch = 21,bty = "n",
lwd=3,
y.intersp=1,
horiz=F,col=c("green", "blue", "red"))

RadarChart
rownames(centros)<-c("Cluster 1", "Cluster 2", "Cluster 3")
centros<-as.data.frame(centros)
maximos<-apply(centros,2,max)
minimos<-apply(centros,2,min)
centros<-rbind(minimos,centros)
centros<-rbind(maximos,centros)
centros
library(fmsb)
radarchart(centros,maxmin = T,axistype = 4,axislabcol="slategray",
centerzero=F,seg=8,cglcol="grey67",
pcol=c("green","blue","red"), col=c("green", "blue","red"))
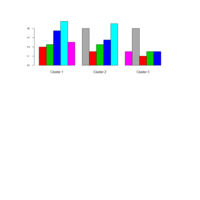
Todos en un solo wrap
barplot(t(centros),beside = T,col = c(2,3,4,5,6,7))
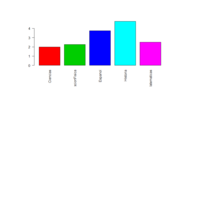
Usar los centros para graficar
library(rattle)#Para centers.hclust
library(RGtk2)
centros<-centers.hclust(Datos1,modelo,nclust = 3,use.median = F)
centros
rownames(centros)<-c("Cluster 1", "Cluster 2", "Cluster 3")
barplot(centros[1,],col = c(2,3,4,5,6,7),las=2)


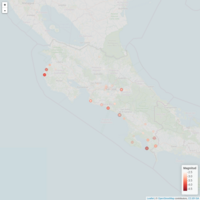
sismosChileMap
library(twitteR)
library(base64enc)
consumer_key <- "jKnww3yOyafYVAnORouNgQ"
consumer_secret <- "OihpKvb278hCkkXBR8uYWSN2KSBx9DLrdeVCKCFuVM"
access_secret <- "0Za4re1f3MQ3FM7BrnO11B07RJzgZVx36wHhLR5I8EcRU"
access_token <- "209266365-xACalTNCPFpeG5Z8oBV50C9YmtnU9Mepn2vgGWHY"
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
usuario<-twitteR::getUser("promidat")#Indicamos el nombre de usuario de interes
usuario$getLocation() #Retorna la ubicacion geografica del usuario.
usuario$description #Retorna la descripcion de la cuenta.
#retorna los ultimos 5 twits
twit<-twitteR::userTimeline(usuario,n=5)
df<-twListToDF(twit)
df$text
#
library(twitteR)
library(stringr)
library(lubridate)
library(leaflet)#Se usa para mapas
library(ggmap)
library(ggplot2)#Se usa para mapas
user <- twitteR::getUser("ovsicori_una")
tweets <- userTimeline(user,n=200)
tweet <- tweets[[1]]$text
tweet
#Funciones para extraer twitts
str_detect(tweet, "Costa Rica")
#Ahora separamos la informacion del texto por coma.
values <- unlist(str_split(pattern = ",",string = tweet))#Ahora es un vector
values
#Extraemos mas datos con referencia a los values
mag<-str_extract(string = values[1],pattern = "[0-9]\\.[0-9]")# estos ultimos numeros extraen la magnitud de un sismo 0-9 pero para algo me servira algun dia jajajaja
mag
#Extraemos mas datos, esta vez de la linea 2
ciudad<-gsub(",*\\sde","",values[2])
ciudad
#Extraemos a que cuenta pertene la reclamacion en la linea 3
pais<-values[5]
pais
#Extraemos la fecha en caso de que aplique
fecha <- str_extract(values[6],"\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}")
fecha
#Ahora que los filtros estan correctamente agrupados, crearemos una funcion que se
#defina a continuacion.
extraer_datos <- function(tuit){
#extraemos el texto
text <- tuit$getText()
#comprobamos que tenga la palabra Costa Rica
if(str_detect(text,"Costa Rica")){
#Separa el texto por comas
values <- unlist(str_split(pattern = ",",string = text))
#Extraemos la magnitud
mag <- str_extract(string = values[1],pattern = "[0-9]\\.[0-9]")
#extraemos la ciudad
ciudad <- gsub(".*\\sde ","",values[2])
#extraemos el nombre de la provincia
provincia <- values[4]
#extraemos el nombre del pais
pais <- values[5]
#extraemos la fecha del sismo
fecha <- str_extract(values[6], "\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}")
#unimos la direccion
direccion <- str_c(ciudad,provincia,pais,sep = ",")
#retornamos la magnitud, ciudad, provincia, pais, fecha y direccion
return(c(mag,ciudad,provincia,pais,fecha,direccion))
}else{
#no el texto hace referencia a otro pais retornamos NULL
return(NULL)
}
}
#Aplicamos la funcion extraer_datos a todos los tuits en la lista
lista_tweets <- lapply(tweets ,extraer_datos)
lista_tweets[1]
#Ahora convertimos de lista a data frame
df_tweets <- do.call(rbind,lista_tweets)
df_tweets <- data.frame(df_tweets,stringsAsFactors = F)
#Anadimos nombres a las columnas
colnames(df_tweets)<-c("Magnitud", "Ciudad", "Provincia", "Pais", "Fecha-Hora", "Direccion")
#Guardamos la magnitud como un numero
df_tweets["Magnitud"] <- as.numeric(unlist(df_tweets["Magnitud"]))
#Convertimos la fecha de tipo texto a tipo fecha
df_tweets["Fecha-Hora"] <- ymd_hm(df_tweets[,"Fecha-Hora"])
head(df_tweets)
#Vamos a hacer un mapa para saber los sitios donde hubieron
#temblores o actividad sismica
direccion <- df_tweets[1, ]$Direccion
direccion
geocode(direccion)
#Con cbind y el comando geocode creamos dos nuevas columnas para lat y lon
#a partir de la columna Direccion para plotearlo en el mapa
df_tweets <- cbind(df_tweets,geocode(df_tweets$Direccion))
head(df_tweets)
#Utilizando la variable magnitud como escala, creamos una escala de tonos rojos
pal <- colorNumeric(
palette = "Reds",
domain = df_tweets$Magnitud)
#Crearemos un mapa interactivo con leadlet paso a paso
#Creamos un mapa vacio (leflet es quien nos permite crear mapas)
mapa <- leaflet()
mapa
#Ahora le agregamos titulos al mapa de OpenStreetMap
mapa <- addTiles(mapa)
#Ahora agregamos marcas (circulos) sobre el mapa
mapa <- addCircles(mapa,
lng = df_tweets$lon, lat = df_tweets$lat,#indcamos la latitud y longitud de las marcas.
weight = 1, radius = df_tweets$Magnitud*1000,#indicamos el radio de la muestra.
popup = str_c("*<b>Ciudad:</b>",
df_tweets$Ciudad,
"<b>Magnitud:</b>",
df_tweets$Magnitud,
"<b>Fecha-Hora:</b>",
df_tweets$`Fecha-Hora`,
sep = "<br/>"),# indicamos la informacion que debe mostrarse al hacer click sobre una marca
color = pal(df_tweets$Magnitud))#indicamos la paleta de color a utilizar.
mapa
#Google map solo permite 2500 consultas por dia a la api
#Agregamos la leyenda al mapa para mayor entendimiento
mapa <- addLegend(mapa,
position = "bottomright",# posicion de la leyenda
pal= pal,#paleta de colores a utilizar
values = df_tweets$Magnitud,#datos de la leyenda
title = "Magnitud",#titulo de la leyenda
opacity = .9 #nivel de opacidad
)
mapa
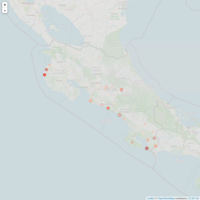
MapaSismosCostaRica
#Mineria web promidat twitter video 4, minuto 56:11
#https://www.youtube.com/watch?v=H1rBoLC1i8I
#[32-bit] C:\Program Files\R\R-3.3.0
library(twitteR)
library(base64enc)
consumer_key <- "jKnww3yOyafYVAnORouNgQ"
consumer_secret <- "OihpKvb278hCkkXBR8uYWSN2KSBx9DLrdeVCKCFuVM"
access_secret <- "0Za4re1f3MQ3FM7BrnO11B07RJzgZVx36wHhLR5I8EcRU"
access_token <- "209266365-xACalTNCPFpeG5Z8oBV50C9YmtnU9Mepn2vgGWHY"
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)
usuario<-twitteR::getUser("promidat")#Indicamos el nombre de usuario de interes
usuario$getLocation() #Retorna la ubicacion geografica del usuario.
usuario$description #Retorna la descripcion de la cuenta.
#retorna los ultimos 5 twits
twit<-twitteR::userTimeline(usuario,n=5)
df<-twListToDF(twit)
df$text
#
library(twitteR)
library(stringr)
library(lubridate)
library(leaflet)#Se usa para mapas
library(ggmap)
library(ggplot2)#Se usa para mapas
user <- twitteR::getUser("ovsicori_una")
tweets <- userTimeline(user,n=200)
tweet <- tweets[[1]]$text
tweet
#Funciones para extraer twitts
str_detect(tweet, "Costa Rica")
#Ahora separamos la informacion del texto por coma.
values <- unlist(str_split(pattern = ",",string = tweet))#Ahora es un vector
values
#Extraemos mas datos con referencia a los values
mag<-str_extract(string = values[1],pattern = "[0-9]\\.[0-9]")# estos ultimos numeros extraen la magnitud de un sismo 0-9 pero para algo me servira algun dia jajajaja
mag
#Extraemos mas datos, esta vez de la linea 2
ciudad<-gsub(",*\\sde","",values[2])
ciudad
#Extraemos a que cuenta pertene la reclamacion en la linea 3
pais<-values[5]
pais
#Extraemos la fecha en caso de que aplique
fecha <- str_extract(values[6],"\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}")
fecha
#Ahora que los filtros estan correctamente agrupados, crearemos una funcion que se
#defina a continuacion.
extraer_datos <- function(tuit){
#extraemos el texto
text <- tuit$getText()
#comprobamos que tenga la palabra Costa Rica
if(str_detect(text,"Costa Rica")){
#Separa el texto por comas
values <- unlist(str_split(pattern = ",",string = text))
#Extraemos la magnitud
mag <- str_extract(string = values[1],pattern = "[0-9]\\.[0-9]")
#extraemos la ciudad
ciudad <- gsub(".*\\sde ","",values[2])
#extraemos el nombre de la provincia
provincia <- values[4]
#extraemos el nombre del pais
pais <- values[5]
#extraemos la fecha del sismo
fecha <- str_extract(values[6], "\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}")
#unimos la direccion
direccion <- str_c(ciudad,provincia,pais,sep = ",")
#retornamos la magnitud, ciudad, provincia, pais, fecha y direccion
return(c(mag,ciudad,provincia,pais,fecha,direccion))
}else{
#no el texto hace referencia a otro pais retornamos NULL
return(NULL)
}
}
#Aplicamos la funcion extraer_datos a todos los tuits en la lista
lista_tweets <- lapply(tweets ,extraer_datos)
lista_tweets[1]
#Ahora convertimos de lista a data frame
df_tweets <- do.call(rbind,lista_tweets)
df_tweets <- data.frame(df_tweets,stringsAsFactors = F)
#Anadimos nombres a las columnas
colnames(df_tweets)<-c("Magnitud", "Ciudad", "Provincia", "Pais", "Fecha-Hora", "Direccion")
#Guardamos la magnitud como un numero
df_tweets["Magnitud"] <- as.numeric(unlist(df_tweets["Magnitud"]))
#Convertimos la fecha de tipo texto a tipo fecha
df_tweets["Fecha-Hora"] <- ymd_hm(df_tweets[,"Fecha-Hora"])
head(df_tweets)
#Vamos a hacer un mapa para saber los sitios donde hubieron
#temblores o actividad sismica
direccion <- df_tweets[1, ]$Direccion
direccion
geocode(direccion)
#Con cbind y el comando geocode creamos dos nuevas columnas para lat y lon
#a partir de la columna Direccion para plotearlo en el mapa
df_tweets <- cbind(df_tweets,geocode(df_tweets$Direccion))
head(df_tweets)
#Utilizando la variable magnitud como escala, creamos una escala de tonos rojos
pal <- colorNumeric(
palette = "Reds",
domain = df_tweets$Magnitud)
#Crearemos un mapa interactivo con leadlet paso a paso
#Creamos un mapa vacio (leflet es quien nos permite crear mapas)
mapa <- leaflet()
mapa
#Ahora le agregamos titulos al mapa de OpenStreetMap
mapa <- addTiles(mapa)
#Ahora agregamos marcas (circulos) sobre el mapa
mapa <- addCircles(mapa,
lng = df_tweets$lon, lat = df_tweets$lat,#indcamos la latitud y longitud de las marcas.
weight = 1, radius = df_tweets$Magnitud*1000,#indicamos el radio de la muestra.
popup = str_c("*<b>Ciudad:</b>",
df_tweets$Ciudad,
"<b>Magnitud:</b>",
df_tweets$Magnitud,
"<b>Fecha-Hora:</b>",
df_tweets$`Fecha-Hora`,
sep = "<br/>"),# indicamos la informacion que debe mostrarse al hacer click sobre una marca
color = pal(df_tweets$Magnitud))#indicamos la paleta de color a utilizar.
mapa

AnalisisSentimientosPopular
ggplot(data=dftotales,aes(x=dftotales$Emociones, fill=dftotales$Emociones,
y=dftotales$Valor))+geom_bar(stat="identity")+
theme(panel.grid.major=element_line(colour = "gray85"),
plot.title= element_text(size = 17),
panel.background= element_rect(fill = "gray100")) +
labs(title="Respuesta a las Publicaciones del Banco Popular Dominicano Periodo Junio - Diciembre (2016)",
x="Categorias", y="Cantidad", fill="Categorias") +
theme(legend.text = element_text(size = 20, color = "gold2"))

ComparacionClustersPopularKmean
barplot(t(grupos$centers),beside = TRUE, main = "Comparacion Clusters",
col=c(2:4))
legend("topright", colnames(info.importante.pagina[c(1:3)]),col = c(2:4), ncol = 2,lty = 1,
lwd = 4, cex = 0.7)

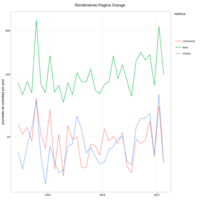
RendimientoPequeno
ajustadito
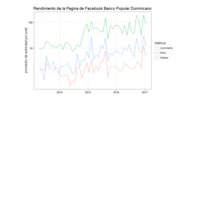
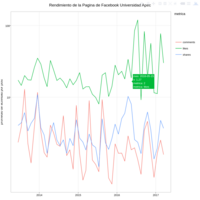
PopularRendimientoPagina
grande

PopularCloud2
Commonality palabras que mas se repiten en los 8 cometarios.















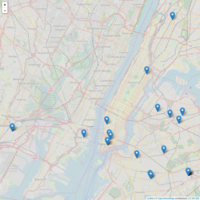
New York Restaurants
People talking about restaurant



Publish HTML
second test