
paterno
Marc Paterno
Recently Published

Data Structure Profling
This document uses some microbenchmarks to choose which data structures to use as candidates for detailed performance studies, to replace std::map<int,int> in the SimPhotonsLite data product.

PDFastSimPAR physics validation: 2 of N
This is the second in my series of physics validation documents for my work on the PDFastSimPAR module. This document looks at the effects of changing the fast_acos algorithm.

Naive Parallel Minimization
This document provides the start of analysis of a naive parallel global minimization based upon random start locations for BFGS local minimization.



Dealing with Multiple Local Minima: the Rastrigin Test Function
This document shows some performance results of using the dlib library’s find_min_global function on the Rastrigin function in 2-5 dimensions.

Verification of HEPnOS and ROOT runs on csresearch
The purpose of this document is to verify that our timing measurements are well-understood.

Expression Template Benchmarking
This document explores the code generation and performance of expression templates in the context of [*dual numbers*](https://en.wikipedia.org/wiki/Dual_number).
In particular, we are concerned with artithmetic operations on dual numbers that occur in the field of automatic differentiation.


CosmoSIS Integration Modules
A brief and informal description of CosmoSIS integration modules.

Data Overview
This is a brief look at the timing data from ICARUS workflow runs using HEPnOS on the csresearch machines.
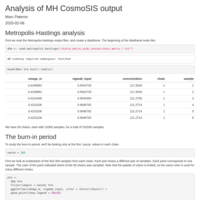
Analysis of MH CosmoSIS Output
This is an example containing a few visualizations of the output of CosmoSIS, using the Metropolis-Hastings sampler with multiple MPI ranks.

Programming GPUs: A taste of CUDA and Kokkos
The goal of this presentation is to give the flavor of GPU programming, as opposed to both CPU (“normal”) programming and the use of GPU-accelerated libraries or tools (such as are common in the machine learning field). It will not be sufficient for you to go out and start programming. I hope it is sufficient to help you decide whether you are interested in further study of GPU programming to support your own work.

Analysis of m-Cubes error estimates
This document contains preliminary analysis of the error estimates returned by the version of the m-Cubes algorithm used in our paper submitted to ISC HP22.
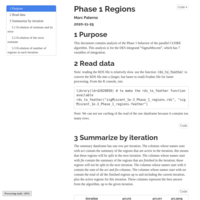
Phase 1 regions
Preliminary analysis of detailed Phase 1 region information, using the DES integrand.

Scaling analysis of per-rank performance of eventselection
This is a preliminary analysis of the scaling of the eventselection program, reading from HEPnOS.

Analysis of per-rank performance of events election
This is a continued analysis of the June 30 eventselection run, using HEPnOS.

PandAna Performance part 3
Preliminary analysis of reading speed of PandAna, and the effect of both HDF5 compression and striping of files on the Cori filesystem.
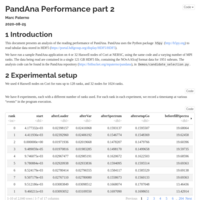
PandAna Performance part 2
Continued analysis of PandAna performance, this time with a larger dataset and more MPI ranks.
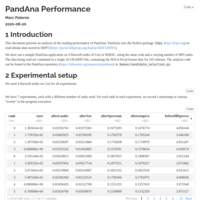
PandAna Performance
This is a (not yet complete) analysis of the parallel performance of PandAna.

A first look at grid job output
Initial results of snapshot runs.

Mathematica integration of Genz_1_abs in 5D
This document shows the results of using Mathematica 12.1.1 to numerically integrate the Genz_1 (absolute value) function in 5.
Timing analysis of June 30 run
Preliminary analysis of timing data from the June 30 HEPnOS run.
Parallel CUHRE subregions
Using the integrand Genz_1abs_5d|, this document contains a very preliminary analysis of the subregions produced by the parallel CUHRE algorithm.

Comparing VEGAS and CUHRE for Genz 1 (absolute value) in 5d
This document shows a comparison of the speed of the VEGAS and CUHRE algorithms, as implemented in the CUBA (http://www.feynarts.de/cuba/) library, and wrapped by cubacpp (https://bitbucket.org/mpaterno/cubacpp).

Genz function 1 in 8d
This document shows a performance comparison between the serial and parallel implementations of the CUHRE algorithm for a non-positive-definite integrand.

Where CUHRE evaluates functions
This document shows where the CUHRE algorithm evaluates the function it is integrating. Unlike a Monte Carlo algorithm (such as VEGAS), CUHRE evaluates the function at a set of determinalistically chosen points.

Comparing VEGAS and CUHRE
This document shows a comparison of the speed of the VEGAS and CUHRE algorithms, as implemented in the CUBA (http://www.feynarts.de/cuba/) library, and wrapped by cubacpp (https://bitbucket.org/mpaterno/cubacpp).

Genz function 1 absolute value in 5d
Preliminary results for integration of non-negative function in 5d.

Reduction phase analysis
Preliminary analysis of reduction data.

Preliminary HEPnOS performance analysis
This is a preliminary analysis of an eventselection run on Theta using 128 nodes.

PanaAna performance measurement scratch pad
This is a public scratchpad for measurements of the evolving performance of PandAna
Scaling of PandAna code
This document describes measurements of the scaling of PandAna code, using as an example the analysis of NOvA data.
It is VERY PRELIMINARY.
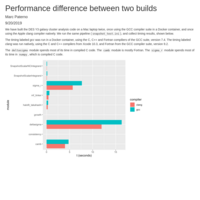
Comparing Two Builds
We compare the speed of execution of DES Y3 galaxy cluster analysis code, as built two different ways.
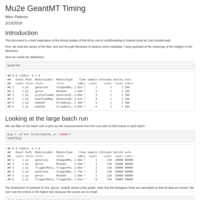
Mu2e GeantMT Timing
A brief study of timing results from the Mu2e Geant4 simulation.

FoF Statistics
Looking to the cause of very slow running of some MOF jobs.

Diagnosing Excessive Memory Usesage
Demonstrates the use of the output of the _art_ framework's MemoryTracker to diagnose a problem of excessive memory usage.
Using rgallery
rgallery is a package for reading HDF5 ntuple files into R.