
deleeuw
Jan de Leeuw
Recently Published

Simultaneous Diagonalization in R/C
We present an R/C implementation of optimal simultaneous diagonalization of several real symmetric matrices using Jacobi plane rotations, with compact triangular storage of symmetric matrices.

Differentiability of Stress at Local Minima
Earlier papers have shown that stress is differentiable at local minima if certain conditions on the weights and dissimilarties are satisfied. In this note we show the result remains true without these additional conditions.

The Positive Orthant Method
The positive orthant method tries to find solutions to consistent systems of inequalities, and approximate solutions to inconsistent systems, by maximizing a fit measure based on the sign function and the absolute value function. We concentrate on systems of linear inequalities and develop a convergent majorization algorithm.

Majorization of Smoothed Absolute Values
We discuss two different even and convex non-negative smooth approximations of the absolute value function and apply them to construct majorization algorithms for least absolute deviation regression. Both uniform and sharp quadratic majorizations are constructed. As an example we use the Boston housing data. In our example sharp quadratic majorization is typically 10-20 times as fast as uniform quadratic majorization.

An Alternative Majorization for Multidimensional Scaling
The Cauchy-Schwartz majorization of the distance function in SMACOF is replaced by a majorization of the squared distance function. This leads to an interesting SMACOF alternative, which we call SMOCAF.

Homogeneity Analysis of Durant Bend Sherds
This paper is a non-technical and mostly graphical introduction to Homogeneity Analysis, also known as Multiple Correspondence Analysis. It is meant as an explanation and justification of a non-standard application of Correspondence Analysis to an example from archeology.

Multidimensional Array Indexing and Storage
We give R, C, and R->C code to access lineary stored multidimensional arrays and compactly stored multidimensional super-symmetric arrays.

Higher Partials of fStress. Who Needs Them ?
We define fDistances, which generalize Euclidean distances, squared distances, and log distances. The least squares loss function to fit fDistances to dissimilarity data is fStress. We give formulas and R/C code to compute partial derivatives of orders one to four of fStress, relying heavily on the use of Faà di Bruno’s chain rule formula for higher derivatives.

Pseudo Confidence Regions for MDS
We compute pseudo-confidence ellipses around MDS solutions, using a new fast implementation of the Hessian of the stress loss function.

Tweaking the SMACOF Engine
The smacof algorithm for (metric, Euclidean, least squares) multidimensional scaling is rewritten so that all computation is done in C, with only the data management, memory allocation, iteration counting, and I/O handled by R. All symmetric matrices use compact, lower triangular, column-wise storage. Second derivatives of the loss function are provided, but non-metric scaling, individual differences, and constraints still have to be added.

acobi Eigen in R/C with Lower Triangular Column-wise Compact Storage
The Jacobi method for computing eigenvalues and eigenvectors of a symmetric matrix is implemented in C using column-wise compact storage of the lower triangle. The complied C code can be loaded into R using the .C() interface. We compare the C implementation with an earlier version in pure R, and with the built-in eigen function in R.

Weighted Low-rank Approximation using Majorization
We give a majorization algorithm for weighted low-rank matrix approximation, a.k.a. principal component analysis. There is one non-negative weight for each residual. A quadratic programming method is used to compute optimal rank-one weights for the majorization scheme.

Some Majorization Theory for Weighted Least Squares
In many situations in numerical analysis least squares loss functions with
diagonal weight matrices are much easier to minimize than least square loss functions with full positive semi-definite weight matrices. We use majorization to replace problems with a full weight matrix by a sequence of diagonal weight matrix problems. Diagonal weights which optimally approximate the full weights are computed using a simple semi-definite programming procedure.

Simultaneous Diagonalization of Positive Semi-definite Matrices
We give necessary and sufficient conditions for solvability of Aj=XWjX′ , with the Aj are m given positive semi-definite matrices of order n. The solution X
is n×p and the m solutions Wj are required to be diagonal, positive semi-definite, and adding up to the identity. We do not require that p≤n.

Infeasible Primal-Dual Quadratic Programming with Box Constraints
This describes a C version of a infeasible primal-dual algorithm for positive
definite quadratic programming with box constraints, proposed by Voglis and Lagaris. We also describe a .C() interface for R.

Factor Analysis as Matrix Decomposition and Approximation: I
A general form of linear factor analysis is defined, and presented as a method to factor a data matrix, similar in many respects to principal component analysis. We discuss necessary and sufficient conditions for solvability of the factor analysis equations and give a constructive method to compute all solutions. A follow up paper will present the corresponding algorithm.

Computing and Fitting Monotone Splines
A brief introduction to spline functions and B-splines, and specifically to monotone spline functions – with code in R and C and with some applications.

Exceedingly Simple Monotone Regression (with Ties)
A C implementation of Kruskal’s up-and-down-blocks monotone regression algorithm for use with .C() is extended to include the three classic ways of handling ties. It is then compared with other implementations.

Exceedingly Simple Monotone Regression
A C implementation of Kruskal’s up-and-down-blocks monotone regressionalgorithm for use wth .C(), and a comparison with other implementations.

Exceedingly Simple Sorting with Indices
We use the system qsort to write a routine that produces both the sort an the order of a vector of doubles.

Shepard Non-metric Multidimensional Scaling
We give an algorithm, with R code, to minimize the multidimensional scaling loss function proposed in Shepard’s 1962 papers. We show the loss function can be justified by using the classical rearrangement inequality, and we investigated its differentiability.

Multidimensional Scaling with Distance Bounds
We give an algorithm, with R code, to minimize the multidimensional scaling stress loss function under the condition that some or all of the fitted distances are between given positive upper and lower bounds. This paper combines theory, algorithms, code, and results of De Leeuw (2017b) and De Leeuw (2017a).

Multidimensional Scaling with Lower Bounds
We give an algorithm, with R code, to minimize the multidimensional scaling stress loss function under the condition that some or all of the fitted distances are larger than given positive lower bounds. Some interesting majorization theory is also given.

Multidimensional Scaling from Below
We give an algorithm, with R code, to minimize the multidimensional scaling stress loss function under the condition that all fitted distances are smaller than or equal to the corresponding dissimilarities.

Quadratic Programming with Quadratic Constraints
We give a quick and dirty, but reasonably safe, algorithm for the minimization of a convex quadratic function under convex quadratic constraints. The algorithm minimizes the Lagrangian dual by using a safeguarded Newton method with non-negativity constraints.

Multidimensional Scaling with Anarchic Distances
Using anarchic distances means using a different configuration for each dissimilarity. We give the anarchic version of the smacof majorization algorithm, and apply it to additive constants, individual differences, and scaling of asymmetric dissimilarities.

Least Squares Solutions of Linear Inequality Systems
We discuss the problem of finding an approximate solution to an overdetermined system of linear inequalities, or an exact solution if the system is consistent. Theory and R code is provided for four different algorithms. Two techniques use active set methods for non-negatively constrained least squares, one uses alternating least squares, and one uses a nonsmooth Newton method.

Discrete Minimax by Quadratic Majorization
We construct piecewise quadratic majorizers for minimax problems. This is appled to finding roots of cubics. An application to a Chebyshev versions of MDS loss is also outlined.

Majorizing Cubics on Intervals
We illustrate uniform quadratic majorization, sharp quadratic majorization, and sublevel quadratic majorization using the example of a univariate cubic.

Derivatives of Low Rank PSD Approximation
In De Leeuw (2008) we studied the derivatives of the least squares rank p
approximation in the case of general rectangular matrices. We modify these results for the symmetric positive semi-definite case, using basically the same derivation. We apply the formulas to compute the convergence rate of Thomson’s iterative principal component algorithm for factor analysis.

Convergence Rate of ELEGANT Algorithms
We compute the convergence rate of the ELEGANT algorithm for squared distance scaling by using an analytical expression for the derivative of the algorithmic map.

Zangwill/Ostrowski Descent Algorithms
This note collects the general results I have used over the years to prove and study convergence of alternating least squares, augmentation, and majorization algorithms. It does not aim for maximum generality or precision.

An Alternating Least Squares Approach to Squared Distance Scaling
Alternating Least Squares and Majorization approaches to squared distance scaling are discussed, starting from a "lost paper" from 1975.

Block Relaxation as Majorization
We show all block relaxation problems can be reformulated as majorization problems.

Pictures of Stress
A low-dimensional multidimensional scaling example is used to illustrate properties of the stress loss function and of different iteration methods

Gower Rank
In Multidimensional Scaling we sometimes find that stress does not decrease if we increase dimensionality. This is explained in this note by using the Gower rank. Two examples with small Gower rank are analyzed.

Exceedingly Simple Principal Pivot Transforms
Principal pivoting transforms are described and implemented using R routines with .C() wrappers.

RPubs by Jan
List of RPubs in 2016

Minimizing qStress for small q
We derive a majorization algorithm for the multidimensional scaling loss
function qStress, with q small.

APL in R
We provide the main functions of the APL array language that do not have R equivalents, using .C() and .Call() for the C interfaces.

In Praise of QR
R and C code for linear least squares, solving linear equations, computing null spaces, and computing Moore-Penrose inverses.

Exceedingly Simple Permutations and Combinations
Generate the next permutation or combination in lexicographic order.

Singularities and Zero Distances in Multidimensional Scaling
We analyze the stationary equations for Euclidean MDS when there are row-singularities, in the form of zero distances, and column singularities , the form of linear dependencies.

More on Inverse Multidimensional Scaling
For a given configuration we find the dissimilarity matrices for which the configuration is a stationary point of the corresponding least squares Euclidean multidimensional scaling problem.

Full-dimensional Scaling
We discuss least squares multidimensional scaling in high-dimensional space, where the problem becomes convex and has a unique solution.

Exceedingly Simple Isotone Regression with Ties
The primary, secondary, and tertiary approach to ties in monotone regressions are implemented in R, on top of the AS 149 Fortran algorithm of Cran.

Second Derivatives of rStress, with Applications
Derivatives of the rStress loss function for MDS are used to derive sensitivity regions and Newton-type algorithms.

Differentiability of rStress at a Local Minimum
The MDS loss function rStress is differentiable, directionally differentiable, or not differentiable, depending on the value of the power r.

Minimizing rStress using Majorization
Majorization is used to construct a class of algorithms that minimize least squares MDS loss functions such as stress used by Kruskal, stress used by Takane et el, and the loss used by Ramsay. More generally, majorization allows us to fit any positive power of Euclidean distances to a matrix of dissimilarities.

Croissants and Wedges in Multiple Correspondence Analysis
This paper discusses the horseshoe or Guttman effect in MCA and reviews various ways of handling curved scatterplots.

Multiset Canonical Correlation Analysis
Canonical correlations for more than two sets of variables, connections with multiple correspondence analysis, an alternative canonical form, and a permutation test.

Homogeneity Analysis
R Code and manual for a general version of homogeneity analysis that uses B-spline bases instead of binary indicators.

Exceedingly Simple Gram-Schmidt Code
Gram-Schmidt (without safeguards and pivots) in C and R.

Aspects of Correlation Matrices
Maximize nonlinear convex functions of the correlation matrix, such as eigenvalues, determinants, and multiple correlations, over monotone and non-monotone spline transformations of the variables.
Matrix Multiplication Animation
For 202BW14
Indexing a Matrix
For 202BW14

Gaussian Elimination
For 202BW14
LDU decomposition and pivots
For 202BW14

Bases, Orthonormal matrices, and Projectors
For 202BW14

Sweeping and the Partial Inverse
For 202BW14

Exceedingly Simple B-spline Code
R and C code to compute B-spline basis functions.

Regression with Linear Inequality Restrictions on Predicted Values
Simple fitting of monotone, non-negative, convex splines and polynomials.

Power Method Animation
For Statistics 102A, Fall 2013

Correlation Ellipses and Eigenvalues
For Statistics 102A, Fall 2013
A Profiling Example
For Statistics 102A, Fall 2013

Fixed Point Iterations
For Statistics 102A, Fall 2013
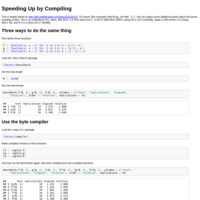
Speeding Up by Compiling
For Statistics 102A, Fall 2013

Connections
For Statistics 102A, Fall 2013
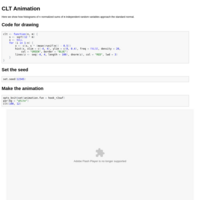
CLT Animation
For Statistics 102A, Fall 2013
Requires R2SWF and Flash

Low Order B-Splines
For Statistics 102A, Fall 2013
Requires R2SWF and Flash
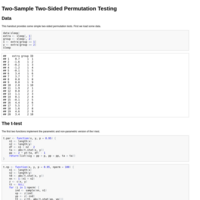
Two-Sample Two-Sided Permutation Testing
For Statistics 102A, Fall 2013

Functions with a variable number of arguments
For Statistics 102A, Fall 2013