
dsollberger
Derek S
Recently Published

Cyberpunk 2077 Mission Flowchart (incomplete)
In this stream, I tried to use the diagrammeR package to create a flowchart of the missions in Cyberpunk 2077. The R code seems to create the mermaid code correctly, but the final output is incomplete.
Statistics about Bisexuality
Rough draft of share of 2020 literature review for the Bisexual Research Group
Statistics about Bisexuality
Rough draft of 2020 literature review for the Bisexual Research Group
DBER Presentation 20200722
DBER talk on "Metrics" for pedagogy studies

Covid-19 Local Trends
Covid-19 Local Trends

MathBio_-_Intro to Bioconductor
MathBio_-_Intro to Bioconductor
resources
Flex Dashboard of links that I have collected
Portfolio 2019
Teaching portfolio toward merit review at my university

Tidy Tuesday: Global Waste data set
This is my first video ever in my idea of creating "beyond the basics" examples of data analysis. Here I walk through
***how to get data from the Tidy Tuesday GitHub page
***exploring the data
***avoiding missing values
***merging data sets
***producing a ggplot graph
Note that this day's endeavor is a really rough draft.

TidyTuesday: Seattle Pet Names
I finally have a few minutes of "What programming do you do on the side?" time to take on my first #TidyTuesday. This week the data set was about pets in the Seattle area. My silly example will be about the first initial of the pets’ names, and then faceted by cats or dogs.

Active and Traditional Teaching
Last Spring semester (of 2018), a couple of biology professors had a natural science experience on their hands. Between Dr. Kamal Dulai and Dr. Mufadhal Al-Kuhlani, one of them taught the Biology 2 course in a “traditional” way while the other employed “active learning” techniques. Here, we will run statistical tests to see if one paradigm is possibly better than the other.

Supreme Court Confirmations
Following up on [Rachel Wellford's tweet](https://twitter.com/rachelwellford/status/1048308997219082240) about Senate votes for Supreme Court confirmations, I decided to try to graph the data.
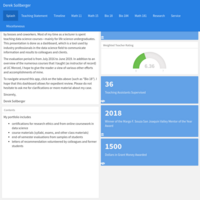
In-n-Out locations that I have visited.
One of my long-standing goals has been to produce a map of all of the In-n-Out locations that I have visited. From taking Rich Majarus' course on DataCamp---[Interactive Maps with leaflet in R](https://www.datacamp.com/courses/interactive-maps-with-leaflet-in-r)---I realized that his package will make this task easy once I get longitude and latitude data.

West of Loathing Elevator Problem
There is a puzzle in the video game West of Loathing where the protagonist needs to apply 3200 pounds of pressure to activate an elevator following the mechanisms were
turning the number 3 bolt applies 411 pounds of pressure
turning the number 5 bolt applies 295 pounds of pressure
turning the number 7 bolt applies 161 pounds of pressure
but if the protagonist applies too much pressure, the situation completely resets. Thus we appear to have encountered the knapsack problem. Perhaps there is a sweet, vectorized way to solve this in R, but for now I will apply brute force. Also, each bolt can only be twisted up to 8 turns.
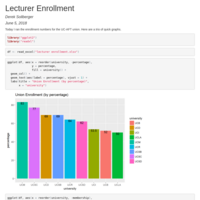
UC AFT Lecturer Enrollment
Today I ran the enrollment numbers for the UC-AFT union. Here are a trio of quick graphs (as of May 2018)

Correlation and Regression
Lecture notes for Bio 18 (at UC Merced) on the topics of correlation and regression

Nonogram Solver (first attempt)
I hope to eventually build a nonogram solver in R.

dplyr switch function
One of my students asked for coding help. I knew that the solution needed a switch statement, but I was not sure how to implement that in R and the dplyr mindset. Fortunately, the powers that be implemented the case_when function about two months ago!
Here is an example on the mtcars dataset. I will take the number of syllables and add a cylinder_description column to write out the words “four”, “six”, and “eight”.

Lecture on p-values
Lecture on p-values
Climate Sentiment Analysis
In this report, I hope to introduce the reader to a little bit of what sentiment analysis can do and explore some data involving climate change reporting in the United States news media.

Doodle Wrangler
My goal here is to load an Excel file from a Doodle poll and then find an optimal pair of times for an event (i.e find a pair of times that is best the highest number of people).

Episode Title Extraction
Here I hope to extract the titles from the episodes of Frasier into an easy-to-use data frame.
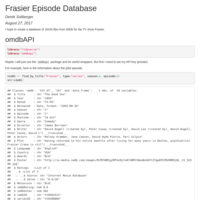
Frasier Episode Database
I hope to create a database for the TV show Frasier.

Wax figures
On July 2, John Oliver had a segment on his TV show "Last Week Tonight" (https://www.youtube.com/watch?v=5cBV8KFFasY) about the auction of life-size wax figures from the presidential wing of a museum in Gettysburg. I instantly wondered "How much did Oliver spend on his 5 figures?". For $n = 5$ figures, the answer is relatively easy to compute, but here I wish to practice some data mining skill in `R`.
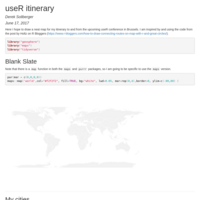
useR itinerary
Here I hope to draw a neat map for my itinerary to and from the upcoming useR conference in Brussels. I am inspired by and using the code from the post by Holtz on R Bloggers (https://www.r-bloggers.com/how-to-draw-connecting-routes-on-map-with-r-and-great-circles/).

Merced Weather Data
In this document, I am wondering if we can replicate the claim that “The Earth has not gotten warmer in the past ten years.” (I have seen this argument in some Twitter conversations.) Here I will discuss how to gather weather data and analyze some of it. Note that this is just one analysis for just one city, and furthermore note that “weather” is not the same as “climate”.
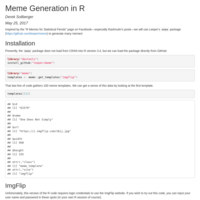
Meme Generation in R
Inspired by the “R Memes for Statistical Fiends” page on Facebook—especially Rashnutin’s posts—we will use Leeper’s meme package (https://github.com/leeper/meme) to generate many memes!

Math 11 Topic Tree
This collapsibleTree R package intrigues me. It was written and hosted by AdeelK93 at https://github.com/AdeelK93/collapsibleTree. Here I hope to use the design to explore my organization of topics for my first-semester Calculus course.

Vignette for the voteogram package
A blogger by the name of hrbrmstr posted a nice article about his voteogram package, and that article was posted on R Bloggers (https://www.r-bloggers.com/plot-the-vote-making-u-s-senate-house-cartograms-in-r/). Here I hope to explore some of the package’s features and abilites.
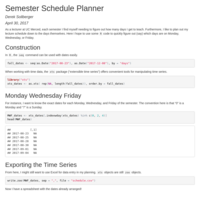
Semester Schedule Planner
As a lecturer at UC Merced, each semester I find myself needing to figure out how many days I get to teach. Furthermore, I like to plan out my lecture schedule down to the days themselves. Here I hope to use some `R` code to quickly figure out (say) which days are on Monday, Wednesday, or Friday.
Surface Plot in Plotly
Some of my students have been asking if there is a way to make interactive, 3D plots in R. Thanks to recent advances, the answer is yes! In this project, we will build a bivariate probability density function and [TO DO] explore its probabilities. Be sure to click (or mouseover) the graphs to get them to appear.

Just Breathe
assembled guitar tab for "Just Breathe" (by Pearl Jam) using the ggguitar package

Coursera Data Science Milestone Report
We are going to produce R code that mimics word-prediction algorithms for mobile text messaging. The joint venture between John Hopkins University and Swiftkey provided training data composed of Twitter posts, blogs, and news feeds. The files are also in the following languages: American English, Finnish, German, and Russian. The algorithm presented below will emphasize speed, and yet will hopefully yield similar results—that is, still predict what would the user wants to type next—as the current, memory-intensive methods.

Capstone
Capstone

Capstone
Capstone

Capstone
Capstone

CapstoneSlidify
Cell Phone Text Prediction
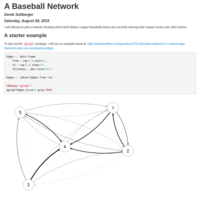
baseballnetwork
A plot of a network of the MLB teams
Confidence Intervals
This code generates several samples, computes their confidence intervals, and checks the intervals versus the true mean

milestoneDS
Data Science Capstone Milestone Report

Batman Optimization
Batman Optimization

Cell Phone Texting Word Prediction
We are going to produce R code that mimics word-prediction algorithms for mobile text messaging. The joint venture between John Hopkins University and Swiftkey provided training data composed of Twitter posts, blogs, and news feeds. The files are also in the following languages: American English, Finnish, German, and Russian. The algorithm presented below will emphasize speed, and yet will hopefully yield similar results---that is, still predict what would the user wants to type next---as the current, memory-intensive methods.

Cell Phone Texting Word Prediction (alternative page)
http://rpubs.com/dsollberger/CapstoneSlidify


milestoneDS
Data Science Capstone Milestone Report

Secant Line Approximations
This Slidify presentation goes into an example of secant line approximations (i.e. toward a tangent) line.

pml
Prediction assignment writeup
for
Practical Machine Learning

Regression Models
course project for the Regression Models class of the Data Science Specialization over at Coursera

Reproducible Research
Peer Assessment 2