
Ksenia_B
Ksenia
Recently Published


Economic stability and Subjective Well-Being
In this project I have analyzed the data of WVS Russia 2011 to find association betwee Subjective well-being and financial security.

Анализ анкетирования абитуриентов НИУ ВШЭ 2019
Представлены результаты анкетирование абитуриентов НИУ ВШЭ Москва в период приемной кампании 2019 года. Проанализированы личные характеристики абитуриентов, результаты ответов на вопросы анкеты, а также результаты оценки некоторых суждений о высшем образовании в целом.


Исследование феномена списывания. Часть 2
В данном проекте с помощью несложных текстового анализа были проанализированы ответы (в свободной форме) на вопросы, касающиеся феномена списывания. В первой части проекта представлена небольшая аннотация, затем представлен анализ текстовых ответов, а также дана интерпретация получившихся результатов.

Employee Churn prevention
In this project I did some exploratory data analysis on the dataset about employees churn. I also build a decision tree to predict emplyee status (still working/terminated) and proposed several measures that might be helpful to prevent churn.

Churn Prediction among Bank Clients
In this project I did exploratory data analysis concerning churn prediction among Bank Clients. To be more precise, deposit makers VS non-deposit maker were analyzed and compared. A bunch of important characteristics were revealed concerning both groups and helping to make future marketing campaigns regarding deposit making more productive.
Churn prediction with logistic regression
In this project I used logistic regression and Random Forest to predict churn for bank clients. Additionally, I did survival analysis to estimate the time before churn.


CMTA Project 1
In this project I have uncovered some differences in speech among male and female users based on their book reviews data.

Coursera
In this project I did an exploratory data analysis from Coursera.org educational platform.

Exploratory Data Analysis of Netflix movies dataset
In this project Netflix movie dataset was analyzed. Interesting insights from the data were visualized. Besides, text analysis was conducted to explore movie overviews and tag lines.Relevan conclusions were made.
Regression modeling
In this project regression analysis was conducted on the ESS 2016 Russia survey data. Several variables were chosen and to build a regression model. Resulting models were estimated via ANOVA in order to identify the best performing one in terms of varianced explained. Additive and Interaction types of regression models were considered.
ANOVA
In this project analysis of variance is applied for the ESS 2016 Russia data. Standard ANOVA tests are conducted, as well as post hoc and non-parametric tests. Also, the effect size of the findings is estimated.
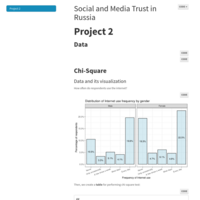
Statistical testing
In this project statistcal testing (Chi-square test, t-tests, post hoc tests and non-parametric tests) were applied using ESS 2016 Russia dataset.
Exploratory Data Analysis of ESS survey data
In this project EDA is conducted on the ESS 2016 survey data.

Movie recommendation system
In this project I have built a movie recommendation system using recommenderlab package in R. Here I try IBCF and UBCF models to find out what is the best performing one. I estimate model performance via ROC curve and Presicion/Recall curve. Finally, I build a function to generate movie recommendations.