
OOGarcia
Oscar Omar Garcia Gonzalez
Recently Published

Caso 25. Muestreo y Tipos de Muestreo
Con un conjunto de datos utilizar mecanismos de programación para determinar muestreos mediante técnicas de aleatorio simple, aleatorio sistemático, aleatorio estratificado y por conglomerados.

Caso 24. Prueba de Significancia de correlación y Prueba de significancia de Pendiente Regresión
Se construyen unos datos relacionados con el caso anterior de llamadas y ventas.
Se determina el coeficiente de correlación de Pearson r
Se determina el valor del coeficiente de determinación r2
Se hace la prueba de significancia para determinar si la correlación estimada de una población es diferente de cero para rechazar o aceptar una hipótesis nula.
Se construye el modelo de regresión linea con la ecuación de mínimos cuadrados Y=a+bx
Se determinan los coeficiente a y b
Se hace una prueba de significancia para evaluar si el valor de la pendiente o valor de b tiene un significado estadístico de manera tal que se pueda rechazar una hipótesis nula.

Caso 23 Regresión Lineal Simple
De un conjunto de datos con dos variables (bivariable) en donde una de ellas es X variable independiente y otra de ellas Y variable dependiente, predecir el valor de Y conforme la historia de X.

Caso 22. Covarianza y Correlación
Se cargan o se construyen datos y se determinan covarizna, correlación y diagrama de dispersión
Antes se cargan las librerías a utilizar

Caso 21- Distribución T Student. Intervalo de confianza
En el sustento teórico, se da a conocer un panorama de la importancia de la distribución T Student comparando la campana de gauss de una distribución normal estándar y distribuciones t; se identifica la fórmula de densidad t y se mencionan las funciones de paquete base de R: dt(), pt(), qt y rt() y la función xpt() y visualize.t de la librería mosaic y visualize()para graficar T Student y para el tratamiento de este tipo de distribuciones. (tdistribution?).
De igual forma el caso ofrece visualización de T Student mediante gráficos programados usando funciones de la librería ggplot2().
En el desarrollo, se resuelven e interpretan algunos ejercicios con datos bajo la distribución T Student,, se identifican ntervalos de confianza con de una distribución T Student.
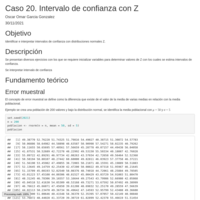
Caso 20. Intervalo de confianza con Z
Se presentan diversos ejercicios con los que se requiere inicializar variables para determinar valores de Z con los cuales se estima intervalos de confianza.
Se interpretar intervalo de confianza.

Caso 19. Distribución Normal Estándar
Representar una distribución normal y transformar a distribución normal estándar

Caso 18. Distribución Normal.
Realizar distribuciones de probabilidad conforme a la distribución de probabilidad normal a partir de valores iniciales de los ejercicios identificando y visualizando la función de densidad y calculando probabilidades.

Caso 17- Distribución Poisson
Realizar distribuciones de probabilidad conforme a la distribución de probabilidad de Poisson a partir del valor medio dado en ejercicios.
Se generan las tablas de probabilidad conforme a distribución Poisson, se identifican los valores de probabilidad cuando la variable discreta x tenga algún exactamente algún valor, ≤ a algún valor o > o ≥, entre otros.

Caso 16. Distribución hipergeométrica
Realizar distribuciones de probabilidad conforme a la distribución de probabilidad de Hipergeométrica a partir de valores iniciales de los ejercicios.
Se generan las tablas de probabilidad conforme a distribución hipergeométrica, se identifican los valores de probabilidad cuando la variable discreta x tenga algún exactamente algún valor, ≤ a algún valor o > o ≥, entre otros.
Se utilizan las funciones base dhyper() y phyper() para la probabilidad y función acumulada de la distribución hipergeométrica.

Caso 15. Distribucion Binomial
Identificar ejercicios casos de la literatura de distribuciones de probabilidad binomial y realizar cálculos de probabilidades, determinar el valor esperado y calcular la varianza y la desviación.
Los ejercicios que se presenta utilizan funciones relacionadas con la distribución binomial dbinom() pbinom(), rbinom() en algunos ejercicios del caso se utiliza la función f.prob.binom() previamente codificada y que encapsula la fórmula para determinar probabilidad binomiales.

Caso 14.Variables aleatorias continuas. Distribucion Uniforme
Realizar ejercicios del uso de variables continuas mediante la distribución de probabilidad uniforme.

Caso 13. Variables aleatorias discretas. Media, varianza y desviación estándar de distribuciones de variables discreta
Desarrollar ejercicios relacionados con variables discretas para
identificar variables discretas, las funciones de probabilidad de cada
variable, la función acumulada, su visualización gráfica para su
correcta implementación.
Se incluye en el caso, media, varianza y desviación estándar de
distribuciones de variables discretas.
Los casos son identificados de la literatura relacionada con variables
aleatorias discretas. Se deben elaborar tres ejercicios en este caso 13
encontrados en la literatura que se encuentran en el caso 14.

Caso 12. Variables aleatorias discretas
Identificar casos relacionados con variables aleatorias discretas para identificar mediante programación R y markdown las variables discretas, las funciones de probabilidad de cada variable, la función acumulada y su visualización gráfica para su adecuada interpretación.

Caso 11. Probabilidad Condicional
De un conjunto de varios ejercicios extraídos de de la literatura de probabilidad de entre libros y sitios WEB se de termina la probabilidad condicional a partir de datos iniciales.
Lo datos iniciales pueden ser la frecuencias, las probabildiad de evento A y evento B así como la probabilidad de intersección entre ambos eventos o conjunto, con ello se determina la probabilidad condicional utilizando la fórmula que se cita más adelante.

Caso 10. Eventos Independientes y Dependientes
Se cargan librerías necesarias Se definen los conceptos eventos dependientes e independientes Se desarrollan ejecicios para eventos dependientes e independientes.

Caso 9 :Operaciones de Conjunto
Se cargan las librerías necesarias para ejecutar funciones
Generar conjuntos de datos
Construir todo el espacio muestral llamado S.muestra
Realizar operaciones de conjuntos
Estimar probabilidades con los conjuntos.
Interpretar probabilidades

Caso 8. Teoría de probabilidad. Ejercicios
Construir ejercicios de probabilidad conforme a partir de datos conforme la teoría de probabilidad.
A partir de un conjunto de datos generados estimar y determinar las probabilidades.

Caso 7. Factorial y Permutaciones
A partir de conjuntos datos (valores individuales) realizar permutaciones para conocer el número de las mismas y el acomodo de los valores para su interpretación en términos de probabilidad.
La diferencias entre permutaciones y *combinaciones* tiene que ver con la cantidad o el número de eventos.
Al hacer permutaciones, si importa el orden en que se acomodan los elementos, es decir en que columna aparecen, en la primera, segunda, tercera y y sucesivamente.
Para identificar el orden, se puede decir que no es lo mismo "Oscar", "Paco" que "Paco", "Oscar", están a la inversa o el orden está invertido. Eso es una diferencia con las combinaciones, son los mismos elementos pero el orden en que se acomodan o en que aparecen los elementos está diferente.
Se deben hacer las siguientes acciones:
- Cargar librerías
- Cargar los datos
- Identificar fórmula de factorial
- Identificar fórmula de permutaciones
- Determinar probabilidades a partir del espacio muestral de las combinaciones
- Encontrar probabilidad con base en frecuencia o contabilizar eventos específicos del espacio muestral
- Interpretar el caso

Caso 6. Factorial y Combinaciones
A partir de conjuntos datos (valores individuales) realizar combinaciones para conocer el número de las mismas y el acomodo de los valores para su interpretación en términos de probabilidad.
Cargar librerías
Cargar los datos
Identificar fórmula de factorial
Identificar fórmula de combinaciones
Determinar probabilidades a partir del espacio muestral de las combinaciones
Encontrar probabilidad con base en frecuencia o contabilizar eventos específicos del espacio muestral
Interpretar el caso

Caso 4. Tablas de Contingencias y medidas de dispersion
- Identificar media de los datos
- Identificar medidas de dispersión, varianza y desviación estándard.
- Generar tablas de contingencia
- Visualizar dispersión de los datos.
- Identificar coeficiente de variación y comparar con similares conjuntos de datos

Caso 5. Tecnicas de conteo. Principio Aditivo, Multipiativo, Diagrama de arbol
- Cargar librerías
- Generar datos a partir de la función *source*()
- Aplicar técnicas de conteo aditivo y multipicativo
- Interpretar resultados de técnicas de conteo
- Interpretar diagrama de árbol
- Interpretar probabilidades elementales

caso 3: Medidas de tendencia central. media, mediana, moda, máximos, mínimos, rango, intervalos, cuartiles, histograma y boxplot
Determinar, interpretar y visualizar medidas de tendencia central de un conjunto de datos de edades, sueldos y calificaciones respectivamente.

CASO 2. Frecuencia de Nombres
Se importan los datos de la dirección: <https://raw.githubusercontent.com/rpizarrog/Trabajos-en-R-AD2021/main/datos/nombres%20y%20apellidos.csv> que contiene nombres de alumnos.
La variable de interés es el nombre.
Se utiliza la función table() para determinar la frecuencia
Se utiliza la función order() para ordenar los valores
Ya con los valores ordenados se genera un diagrama de barra por medio de la función codebar().
Se hace una interpretación del caso.
Se visualizan los primeros diez y últimos diez registros u observaciones de los alumnos.
¿Cómo se hace el caso o como se desarrolla?

Caso 1. Analisis de promedios de alumnos
Analisis de promedios de alumnos utilizando diversos metodos para obtener:
Mostrar solo los primeros diez registros y los últimos diez registros.
Identificar la variable de interés llamada promedio.
Determinar una muestra de 300 registros de la población. La población es todos los registros del archivo y la muestra es una parte de la población
Identifica la media de la población
Identificar la media de la muestra
Comparar las medias aritméticas
Crear un histograma de los datos
Realizar interpretación

Importar datos de personas URL
Importar datos de personas URL