
maechler
Martin Maechler
Recently Published

Rounding to Decimal Digits in Binary
`round(x, digits)` is not as simple as you may think: R's double precision numbers are binary and use base 2 arithmetic. Consequently, base 10 rounding is nontrivial. I've provided a new algorithm for R 4.0.0 and CRAN package `round` provides motivation and comparison between algorithms.

gsub(*, fixed=TRUE) partly avoids "quotation hell"
How to change some "escape" hell code (from base R code) with `fixed=TRUE`
to gain both
- clarity and
- speed


R Language Objects
Since in R,
> *Everything that happens is a function call*
> *Everything that exists is an object* (John Chambers)
it is particularly important to understand those objects that *are* function calls.
Beginners learn about numeric and character vectors, data frames; factors, and then about functions, once they advance slightly. One of the next steps towards mastering R is learning about "language" objects. An R master will also understand Thomas Lumley's `fortunes::fortune("answer is parse")`.

why Namespaces in R are useful and important
Different packages (and the useR) may like to use their own versions of functions called 'filter' or 'head' or ...
Hence potential name "conflicts".
Namespaces allow to specify *which* version of 'filter' or (the variable) 'pi' will be used

Fast lm() since R 3.1.0
In spring 2014, I have introduced a very bare bone version of `lm()` into R, from version 3.1.0 on, which is even an order faster than `lm.fit()`.

Complex NA's and NaN's in R
R’s complex type (class) also supports missing values, i.e., NA's, and NaN (“Not a Number”) values as the numeric (double) is known for.
However, complex vectors (or matrices) are used much more rarely, and some details of R’s implementation have been unchanged since written in the early days of R (in the 90’s), even though they have not been quite consistent with the handling of NA and NaN for numeric objects.
sub() or substr() / substring() ?
Very short benchmarking of sub() vs substr() etc....
actually related to the R source code itself
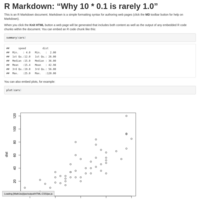
ProgRRR_2015-first
The first week (2015-02) "Programming with R for Repr.Resaeach" Cource:
-- Why 10 * 0.1 is rarely 1 --
R's FAQ 7.31 etc
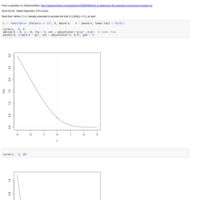
L-gaussian-loss
An extended answer for a question on stackoverflow:
- Inverse function via `uniroot()`
- Vectorizing (using vapply() and logical indexing (instead of ifelse(.))
- sfsmisc::eaxis()