simon
Meng-Hsien Shih
Recently Published

Sentiment Analysis of Sarcasm: A Distributional Pattern of Sentiment Score within Sarcastic Tweets
Sarcastic sentences, which are intended to express the opposite sentiment of its surface form, have been a problem in sentiment classification. The purpose of our study is to use data acquired from Twitter to examine possible features of sarcasm in order to help improve accuracy in sarcasm detection. Our data come from tweets with the hashtag of #sarcasm, which indicates the speaker’s intention to be sarcastic. We have testified the functions of the following features: (1) the emotion performance of sarcastic tweets is more positive, (2) the relationship between the original tweets and the “@To User” tweets is with the same sentiment score, (3) the use of degree adverbs in sarcastic tweets, and (4) the high frequent words used in sarcastic tweets. We also examine a pattern of sentiment change within a sarcastic expression. Based on the results, we carried out two classification tasks of sarcasm detection and obtained a best performance of 83.3%, which shows that degree adverbs and the sentiment pattern within a sarcastic tweet proved to play an important role in the sentiment analysis of sarcasm.

Normal Distribution in Corpus Linguistics?
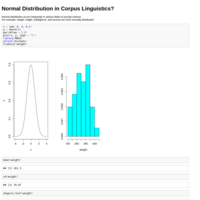
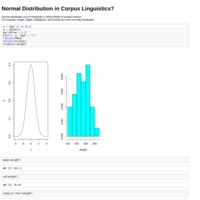
Normal distribution occurs frequently in various fields of (social) science.
For example, weight, height, intelligence, and income are most normally distributed.
It would be surprising if there is not any normal distribution in language?
So can we find such distribution in a Chinese corpus??
Let’s take sentence length in part of the ASBC as the first investigation.
Unfortunately, sentence length is not normally distributed.
How about specific word frequency in a chunked balanced corpus?
It seems normally distributed, but is it just a chance?
Let's re-examine the normality with the corpus size varying.
Or we can further examine the normalities of corpora with less than 2000 words.
In conclusion, a specific word frequency (e.g., 的(DE)) in a chunked Chinese balanced corpus with more than 2000 words is normally distributed.
In the future, 10-fold cross validation of the corpus and test for other words should be performed.
If it is true, normality could be regarded as one of the criteria for a good-enough corpus.