
tevfik1461
tevfik bulut
Recently Published



Normalize Edilmiş Maksimum Değerler [NMD] Metodu
Çalışma kapsamında, çok kriterli karar verme (ÇKKV) problemlerinin çözümünde kullanılmak üzere uygulanması oldukça kolay ağırlıklandırma metodu geliştirilmiştir. Bu çalışma ilk olarak 2017 yılında www.tevfikbulut.com adlı kişisel web sitemde yayınlanmıştır. Bu çalışmayla 2017 yılında yayınlanan ancak matematiksel notasyonları eksik olan normalize edilmiş maksimum değerler $(NMD)$ metodunun bu kısmı tamamlanmıştır. Microsoft Excel üzerinde yapılan simülasyon çalışması ile de yöntemin somutlaştırılması amaçlanmıştır.

Logaritmik Konsept Yaklaşımı [APLOCO]
Çalışma kapsamında çok kriterli karar verme (ÇKKV) yöntemi olarak geliştirilen Logaritmik Konsept Yaklaşımı (APLOCO)'nın uygulama adımlarının tanıtılmasıdır.

Bulut Endeksi [BE] Simülasyonu
Çalışma kapsamında çok kriterli karar verme (ÇKKV) yöntemi olarak geliştirilen Bulut Endeksi (BE) uygulama adımlarının tanıtılmasıdır.

Duygu Analizi Üzerine Bir Vaka Çalışması
Duygu analizi, yapılandırılmamış metin verilerinin büyüklüğü nedeniyle artan bir araştırma ve uygulama alanıdır.Duygu analizi için tercih edilen programlama dilleri arasında Python ve R gibi diller öne çıkmaktadır.Duygu analizi modelleri, yalnızca kutupluluğa (olumlu, olumsuz, tarafsız) değil, aynı zamanda duygu ve duygulara (kızgın, mutlu, üzgün vb.) ve hatta niyetlere de odaklanmaktadır.Duygu analizi, metin içine sinen duyguları bulmak için kullanılan bir Doğal Dil İşleme (NLP) uygulamasıdır. Günümüzde, Facebook, Twitter gibi sosyal web siteleri, film, haber, yemek, moda, politika ve çok daha fazlası gibi farklı şeyler hakkında kullanıcıların yorumlarını görmek ve değerlendirmek için yaygın olarak kullanılmaktadır. İncelemeler ve görüşler, kullanıcıların belirli bir varlıkla ilgili memnuniyet düzeyini belirlemede önemli bir rol oynar. Bunlar daha sonra polariteyi, yani pozitifliği, negatifliği ve nötrlüğü bulmak için kullanılır. Duygu analizi pek çok farklı alanda kendine kullanım alanı bulmaktadır.Bunlardan bazıları aşağıdaki şekilde verilmiştir.



Şifre Kombinasyonlarının Kırılma Olasılıkları
In this study, the probability of breaking password combinations with the function I created using R programming language was calculated by considering different dimensions. The different dimensions considered are:
How much does the number of digits in the password combination affect the probability of cracking?
How much do the characters in the language used in the password combination affect the probability of cracking?
How does the repetitive and non-repeatable password combination affect the probability of cracking?
How much does the number, letter or both (alphanumeric) used in the password combination affect the probability of cracking?
How much do the symbols and lowercase letters used in the password combination affect the probability of cracking?

Türkçe ve İngilizce Şifre Üretme Algoritması
In this study, it is aimed to create awareness in the subject area by making password generation practices with both English and Turkish characters.

Kaynakça Düzenleme Üzerine Vaka Çalışması
In this study, the issues of how to display the loading information and bibliography part of the libraries used in the table format are discussed. More importantly, while using R programming language, its integration with css, html and javascript programming languages was examined and how it played a role in the design of the tables was examined.

Markov Zinciri Üzerine Vaka Çalışmaları
In this study, it is aimed to raise awareness by showing Markov chain terminology, which has an important place in data science, and its applications in R.


Makine Öğrenme Yöntemleri İle Eksik Gözlemlere Atama Yapma
Missing observations in the variables in the data set, in other words missing data, come at the beginning of the problems faced by data scientists or academicians and field workers dealing with data analysis. Although there are many methods among the missing data assignment methods in the literature, some of the prominent methods are as follows:
Assign mean values to missing observations
Assigning 0 to missing observations
Assign median value to missing observations
Assignment to missing observations by PMM method
Assignment to missing observations by regression method
Assigning missing observations by EM (Expectation-Maximization) method
Apart from these mentioned methods, machine learning algorithms or methods can also be used to assign missing data. Some of them can be summarized as follows:
Assigning missing observations with decision trees method
Assigning missing observations with KNN (K Nearest Neighbor) method
Assignment to missing observations with Random Forest (RF) algorithm

Verinin Standartlaştırılması Üzerine Vaka Çalışmaları: Case Studies on Data Standardization
The main focus of this study is the practical handling of some standardization methods that have found application in the literature.The standardization methods commonly used in the literature are as follows:
Z-Score Standardization
Standardization with a Distribution Range of 1
Standardization with a Distribution Range (-1;+1)
Standardization with a Distribution Range (0;+1)
Standardization with Maximum Value of 1
Standardization to Arithmetic Mean 1
Standardization with a Standard Deviation of 1


Verinin Standartlaştırılması Üzerine Vaka Çalışmaları: Case Studies on Data Standardization
The main focus of this study is the practical handling of some standardization methods that have found application in the literature.The standardization methods commonly used in the literature are as follows:
Z-Score Standardization
Standardization with a Distribution Range of 1
Standardization with a Distribution Range (-1;+1)
Standardization with a Distribution Range (0;+1)
Standardization with Maximum Value of 1
Standardization to Arithmetic Mean 1
Standardization with a Standard Deviation of 1


Quandl Kütüphanesi İle Veri Çekme ve Dinamik Grafik Oluşturma
Çalışma kapsamında Quandl R paketi ile veri setlerinin nasıl çekildiği, meta verinin nasıl elde edildiği, özellikle zaman serileri bulunan veri setlerinde dinamik grafiklerin nasıl oluşturulduğu dygraphs, quantmod ve plotly paketleri kullanılarak ele alınmıştır.


Dinamik Grafik Oluşturma Üzerine Vaka Çalışması
Çalışma kapsamında TÜİK veri tabanında yayınlanmış nüfus istastiklerinden yararlanarak uygulamalı dinamik grafik oluşturma çalışması yapılmıştır. Bu amaçla R programla dilinde kayıtlı olan ağırlıklı ggplot2, plotly ve dplyr kütüphaneleri kullanılmıştır.

Crostalk ve Leaflet Paketleriyle Türkiye Depremlerinin Analizi
Çalışma kapsamında Türkiye’de son 1 yıl içerisinde gerçekleşen depremlerin keşifsel veri analizi yapılmıştır.

Türkiye Depremlerinin Keşifsel Analizi
Çalışma kapsamında Türkiye’de son 1 yıl içerisinde gerçekleşen depremlerin keşifsel veri analizi yapılmıştır. Bu çalışmada prettydoc paketinde bulunan cayman teması kullanılarak R Markdown üzerinde html uzantılı raporlama yapılmıştır.

R Markdown Örnek Uygulama Raporu 3
R Markdown üzerinde daha önce **prettydoc** paketi kullanılarak **html** uzantılı raporlama yapmıştım. Bu çalışmada ise **prettydoc** paketinde **architect** teması kullanılarak R Markdown üzerinde **html** uzantılı raporlama yapılmıştır.

R Markdown Örnek Uygulama Raporu 2
R Markdown üzerinde daha önce prettydoc paketi kullanılarak html uzantılı raporlama yapmıştım. Bu çalışmada ise prettydoc paketinde leonids teması kullanılarak R Markdown üzerinde html uzantılı raporlama yapılmıştır.

R Markdown Örnek Uygulama Raporu
Bu çalışmanın amacı prettydoc paketi kullanılarak R Markdown üzerinde html uzantılı raporlama yapmaktır.

"crosstalk" Paketi İle Dinamik Tablo Oluşturma Üzerine Bir Vaka Çalışması II: A Case Study on Creating Dynamic Tables with Package "Crosstalk" II
R'da başta shiny olmak üzere flexboard ve crosstalk paketleri dinamik tablo oluşturmada kullanılan paketlerden bazılarıdır. Bu çalışmada ise bir önceki çalışmadan farklı olarak crosstalk ve datatable paketleri birlikte kullanılarak adım adım özgün bir uygulama üzerinde gösterilecektir. Önceki çalışmamızda oluşturulan dinamik tabloya ek olarak bu çalışmada aynı zamanda farklı formatlarda verinin indirilmesine ve yazdırılmasına imkan tanınmıştır.
alışmada kullanılan veri seti TÜİK veri tabanından alınan 15 yaş üstü nüfusun yıllara ve illere göre dağılımını içermektedir. 15 yaş üstü nüfus, Adrese Dayalı Kayıt Sistemi (ADKS)'ne göre elde edilen verilerden oluşmakta olup, 2008-2019 dönemlerini kapsamaktadır.
"crosstalk" Paketi İle Dinamik Tablo Oluşturma Örneği
Başta "crosstalk" ve "reactable" paketleri kullanılarak veri setinin online ortamda kullanılmasına esneklik ve ulaşılabilirlik kazandırılması amaçlanmıştır.

Exploratory Data Analysis of Turkey Earthquakes
Data set includes earthquakes with magnitude between 4.0 and 8.0. Number of observations is 6510, and number of variables revised is 12. Earthquake data set is consisted of time series from year 1900 to date 2020-02-08.

Analysis of Turkey Earthquake Data
The main purpose of the study is to analysis Turkey earthquake data set obtained AFAD (The Disaster and Emergency Management Presidency) online data base using data mining techniques. In this way, it is targeted to be created awareness.
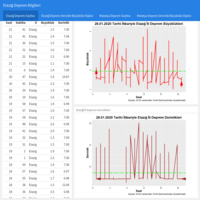
A Case Study on "Flexboard" Application
On 26.01.2019, a flexboard application was conducted using the earthquake data of Elazig province, which was taken from AFAD (The Disaster and Emergency Management Presidency). In this study, package "flexboard" is used. First of all, basic data set of the earhtquake is given, and charts defining correlation between magnitude of the earthquake and depth of the earthquake are plotted. In conclusion, results of pearson correlation are presented. The findings show that there is a strong correlation between magnitude of the earthquake and depth of the earthquake for Malatya city.